| Предыдущий раздел |
Здесь будет дан обзор методов реализации церковно-славянского письма в современных кодировочно-шрифтовых системах. Как делают надстрочники, как размещают большое количество символов и лигатур, на какой основе разрабатывают инструментарий для работы с текстами. Предполагается, что читатель знаком с понятиями "кодовая страница", Unicode, 8- и 16-разрядные приложения. Почитать об этом можно здесь.
![]()
Первый вопрос, возникающий при проектировании церковно-славянской кодировочно-шрифтовой системы (КШС) -- где в кодовом пространстве размещать основные символы? Как было сказано в обзоре церковно-славянского письма, этому языку даже в позднем изводе, даже без учета лигатур требуется порядка полусотни символов строчного регистра и чуть меньше -- заглавного. Не так уж много и для 8-битной, и для 16-битной кодировки. Но как разместить их наиболее корректно? Вспомним, распространенные операционные системы изначально не поддерживают церковно-славянский язык, эту поддержку приходится делать самим. Логичнее было бы, если позволяет ситуация, строить КШС на основе какого-то уже имеющегося в системе близкого к ЦС языка, дабы, во-первых, минимизировать работы по дополнению системы и, во-вторых, при отсутствии достроенной нами системной поддержки ЦС можно было бы хоть как-то работать с ЦС текстами, опираясь на возможности по вводу на родственном языке.
Ближайший родственный к церковно-славянскому и имеющий системную поддержку язык -- современный русский. Большая часть церковно-славянского алфавита имеет свои аналоги в русском. Более того, Unicode предписывает размещать эту большую часть ЦС-алфавита на кодовых позициях русских букв. Неудивительно поэтому, что большая часть существующих КШС основана на кодировках русского языка.
(Однако даже здесь имеются экзотические исключения. Мне встречались КШС, разработанные, вероятно, на западе в условиях отсутствия поддержки русского языка, где даже имеющие русские аналоги буквы ЦС размещались на латинском регистре.)
Хорошо, а где размещать остальные символы? Вот тут начинаются
расхождения. Чаще всего "нерусские" буквы размещаются на латинском
регистре. Он доступен для ввода без дополнительных переделок раскладки, следовательно,
и системной поддержки особой не потребуется. При таком размещении имеют хождение
следующие традиции: омографическая, фонетическая и "клавиатурная".
При омографической традиции буквы размещаются на латиннице по принципу похожести
изображения латинской и церковно-славянской букв. Например: ![]() -- i,
-- i, ![]() -- w,
-- w, ![]() -- v,
-- v, ![]() -- s. Фонетический принцип связывает сходные по звучанию латинские и
церковно-славянские буквы, или даже выстраивает цепочку "ЦС-буква -- греческий
исходник -- латинский аналог". Например:
-- s. Фонетический принцип связывает сходные по звучанию латинские и
церковно-славянские буквы, или даже выстраивает цепочку "ЦС-буква -- греческий
исходник -- латинский аналог". Например: ![]() -- p,
-- p, ![]() -- x,
-- x, ![]() -- u,
-- u, ![]() -- t. Наконец, "клавиатурный" принцип работает по цепочке "славянская
буква -- похожая по звучанию русская буква -- нарисованная на той же клавише
латинская буква". Примеры:
-- t. Наконец, "клавиатурный" принцип работает по цепочке "славянская
буква -- похожая по звучанию русская буква -- нарисованная на той же клавише
латинская буква". Примеры: ![]() -- z,
-- z, ![]() --
b,
--
b, ![]() --
j. Первые два принципа способствуют "благообразности изнанки" (относительной
узнаваемости и читаемости текста в условиях отсутствия церковно-славянского
шрифта), последний -- легкому (по крайней мере, некоторые так утверждают) запоминанию
раскладки в условиях отсутствия системной поддержки церковно-славянского ввода.
Реальные КШС представляют собой применение трех этих принципов в приблизительно
равных пропорциях.
--
j. Первые два принципа способствуют "благообразности изнанки" (относительной
узнаваемости и читаемости текста в условиях отсутствия церковно-славянского
шрифта), последний -- легкому (по крайней мере, некоторые так утверждают) запоминанию
раскладки в условиях отсутствия системной поддержки церковно-славянского ввода.
Реальные КШС представляют собой применение трех этих принципов в приблизительно
равных пропорциях.
Легко заметить, что такое размещение хорошо приспособлено для 8-разрядных кодировок и отсутствия какой-либо поддержки ЦС на системном уровне. Действительно, исторически такое размещение появилось в период отсутствия серьезной системной поддержки ЦС. Это решение достаточно надежно с точки зрения совместимости: латинские буквы в шрифте доступны всегда, русские на русифицированных системах -- тоже. Это же можно сказать и о клавиатурных раскладках. Кроме того, занятие латинских знакомест не несет особой опасности: очень сложно представить себе ситуацию, когда в документе перемежаются латинский и церковно-славянский текст, причем так, что форма латинских букв должна быть стилизирована под форму церковно-славянских. Следовательно, помещать и латинские, и церковно-славянские буквы в одном шрифте особого смысла нет.
И все-таки, занятие латинских знакомест имеет свои недостатки. Да, мы легко можем издавать тексты такими шрифтами на бумаге. Но что, если мы за хотим поместить их в Интернет? Ведь у читателя нашей страницы могут не оказаться установленными наши церковно-славянские шрифты. С греческим языком, скажем, в этом смысле проблем нет. Нам достаточно либо указать в заголовке, что кодировка греческая, либо создавать страничку в UTF или Юникоде -- и тогда браузер сам найдет и использует установленные в системе греческие шрифты. В крайнем случае, однократно предложит загрузить поддержку греческого языка с сайта производителя браузера. С церковно-славянскими же текстами, у которых часть букв на латиннице, этот метод не сработает: браузер покажет латинницу. Ибо откуда ему знать? Мы же заняли латинские позиции нелегально. То есть, для интернационального обмена необходимо поользоваться узаконенными для ЦС кодовыми позициями.
А существуют ли они вообще, эти узаконенные позиции? Что говорит Unicode о церковно-славянском языке?
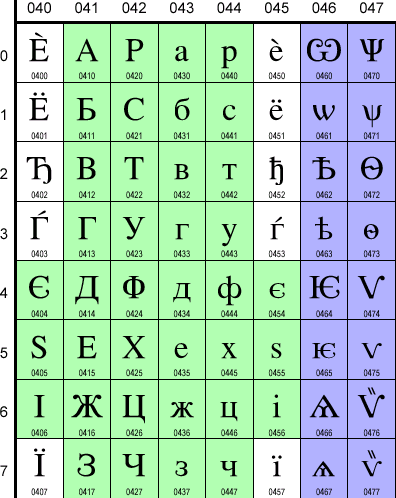
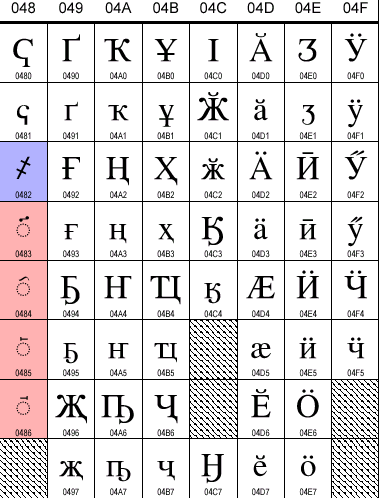
Да, в Юникоде есть место для ЦС. Практически все "нерусские" буквы новоцерковно-славянского "извода" в Юникоде предусмотрены. Их коды расположены в кириллическом диапазоне 0400..04FF, среди прочих букв славянских и постсоветстких народов. Часть церковно-славянских букв, как я уже говорил, разделяет позиции со своими русскими аналогами. Вот таблица кириллического диапазона, взятая с www.unicode.org:
 |
 |
 |
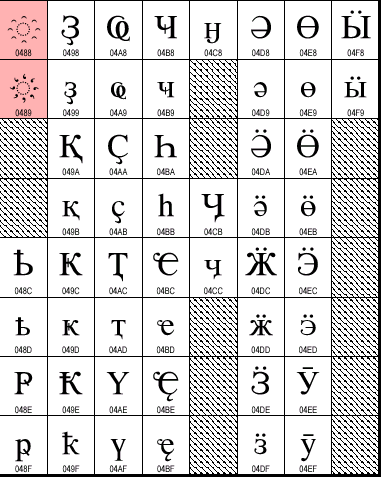 |
Я немного раскрасил ее. Здесь синим цветом помечены церковно-славянские
символы, для которых Юникодом выделены отдельные позиции, зеленым -- те, которые
разделяют свои позиции с символами современных национальных алфавитов, красным
-- те, которые, возможно, имеют отношение к церковно-славянскому языку.
Я взял на себя смелость сопоставить славянской букве ![]() "украинскую и"
"украинскую и" ![]() ,
а не
,
а не ![]() (йи),
потому что, несмотря на графическую схожесть к "йи" церковно-славянская
i-десятичная ближе к i-украинской семантически. Unicode, вероятно, того же мнения,
ибо он называет букву на позиции 0456 одновременно "CYRILLIC SMALL LETTER
BYELORUSSIAN-UKRAINIAN I" и "Old Cyrillic i". То же самое можно
сказать и о славянской
(йи),
потому что, несмотря на графическую схожесть к "йи" церковно-славянская
i-десятичная ближе к i-украинской семантически. Unicode, вероятно, того же мнения,
ибо он называет букву на позиции 0456 одновременно "CYRILLIC SMALL LETTER
BYELORUSSIAN-UKRAINIAN I" и "Old Cyrillic i". То же самое можно
сказать и о славянской ![]() и украинской
и украинской ![]() :
буква на позиции 0454 называется "CYRILLIC SMALL LETTER UKRAINIAN IE"
и "Old Cyrillic yest". Под буквами на позициях 047С и 047D подразумевается,
вероятно, "омега-красивая"
:
буква на позиции 0454 называется "CYRILLIC SMALL LETTER UKRAINIAN IE"
и "Old Cyrillic yest". Под буквами на позициях 047С и 047D подразумевается,
вероятно, "омега-красивая" ![]() ,
хотя на рисунке изображена "омега под титлом", да и в описании эти
символы даются как CYRILLIC LETTER OMEGA WITH TITLO.
,
хотя на рисунке изображена "омега под титлом", да и в описании эти
символы даются как CYRILLIC LETTER OMEGA WITH TITLO.
Чтобы обеспечить потребности позднего извода, нам потребуется
еще две позиции для ![]() (i десятичного без точек для записи цифр), и одна -- для
(i десятичного без точек для записи цифр), и одна -- для ![]() (ик, цифра 400). Кроме того, в части знаков препинания необходим символ кавыки
(ик, цифра 400). Кроме того, в части знаков препинания необходим символ кавыки
![]() .
.
Нетрудно видеть, что по части основных символов Unicode предоставляет нам кодовые позиции для практически всех букв из новоцерковно-славянского языка, и многое из древнего ЦС. Почему же не проектировать шрифты с размещением церковно-славянских букв сразу же на их легальных позициях?
Здесь имеются препятствия, связанные с реальными операционными системами. Например, в Windows позиции, закрашенные у меня синим цветом, не содержит ни одна кодовая страница. Следовательно (это описано в статье о кодировках), в части этих символов у нас будут огромные проблемы с 8-битными приложениями, с клавиатурным вводом, да и с надежностью отображения даже в 16-битных приложениях (Word 97-2000, например, "синие" символы откажется кернинговать). Отчасти это вполне объяснимо, во-первых, тем, что потребители возможных систем для работы с церковно-славянскими текстами вряд ли способны оплатить поддержку этого языка на системном уровне самими разработчиками ОС, а, во-вторых, тем, что Unicode по своей природе мало оглядывается на возможности практической реализации функций, предписываемых этим стандартом. Например, в Юникоде есть забавный раздел "Combining Marks for Symbols" (20D0..20FF), в котором имеется масса красивых по идее, но сомнительных по конкретике составных символов. К примеру, символ 20DD предписывает обвести предыдущий символ окружностью. Хорошая идея, но как вы представляете себе реальный шрифт, способный красиво обвести любую по форме и размерам предшествующую букву?
В общем, даже по вопросу расположения основных символов очевидна необходимость разработки двух типов шрифтов: корректно работающих в верстальных и текстовых процессорах, и корректно отображающихся в Интернете без необходимости загрузки "самопальных" шрифтов. Двух типов, в принципе несовместимых друг с другом. И, подчеркну, даже только в вопросе расположения основных символов. Ибо, как станет ясно из дальнейшего повествования, Юникодом не предусмотрено всех возможностей, необходимых для легального отображения надстрочных знаков церковно-славянского письма, и, следовательно, вопрос о разработке полностью легальных церковно-славянских шрифтов можно на данном этапе смело закрывать.
На мой взгляд, сделать здесь пока ничего нельзя. Разве что кто-то украдет исходники Windows, MS Office и пр., и доделает их, наконец. Либо все "славянисты" дружно перейдут на Linux, а кто-то, опять же, сделает поддержку ЦС в Linux. Последнее (я имею в виду, написание поддержки, а не тотальный переход) намного реальнее, ибо исходники этой ОС вполне доступны и открыты.
| Предыдущий раздел |